ISB-CGC Data Overview
ISB-CGC provides access to data from several research programs, such as The Cancer Genome Atlas (TCGA), Therapeutically Applicable Research to Generate Effective Treatments (TARGET), and Cancer Cell Line Encyclopedia (CCLE). The full list can be seen in the Program filter of the ISB-CGC BigQuery Table Search.
The majority of the data made available through ISB-CGC originates from NCI Genomic Data Commons (GDC). Users can access GDC data on the cloud through ISB-CGC. Users have access to processed data from cancer patients.
NCI Proteomics Data Commons (PDC) data is also available in ISB-CGC Google BigQuery tables.
In general, almost all raw data is controlled-access; as of August 2024, ISB-CGC no longer provides access to controlled-access data.
The GDC has established bioinformatics workflows/pipelines executed on the raw data to generate processed data. In this way, users can directly access the processed data without having to run compute-intensive workflows themselves. However, users can still run their own workflows/pipelines.
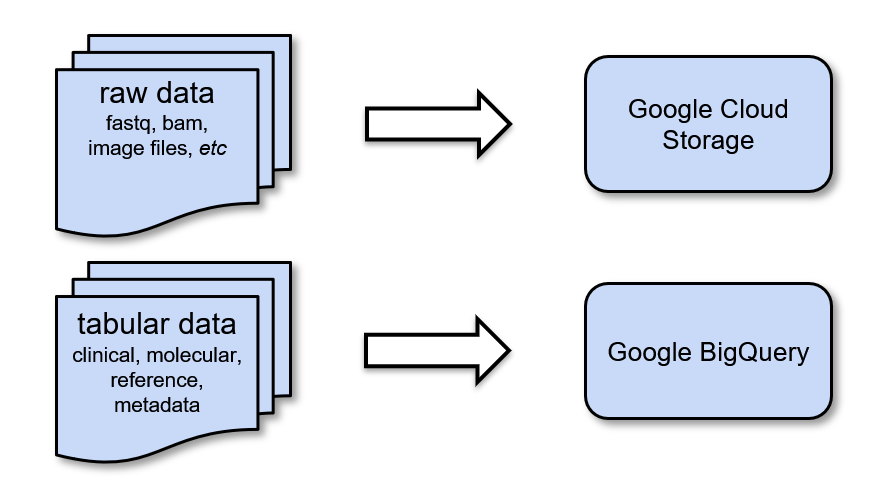
Processed data, however, are generally open-access. ISB-CGC allows users to utilize this processed data in two ways on the platform:
Google Cloud Storage: Individual GDC processed data files are accessible through GDC Google Cloud Storage buckets; ISB-CGC provides pointers to these files.
Google BigQuery: Processed data are consolidated by datatype (ex. Clinical, DNA Methylation, RNAseq, Somatic Mutation, etc.) and transformed into ISB-CGC Google BigQuery tables for ease of access and analysis. This novel approach allows our users to quickly analyze information from thousands of patients in our curated BigQuery tables.
Google Cloud Storage
Google Cloud Storage (GCS) is a cloud-based object-store that is used to store many types of (usually binary) data, typically processed by custom software pipelines. The data hosted by GDC is contained within Google Cloud Storage. Metadata stored within ISB-CGC BigQuery tables contains pointers to file locations in this GDC data.
Google BigQuery
Google BigQuery (BQ) is a columnar database ideal for storing tabular data. Its query speed is automatically scaled by multiprocessing. Data is accessed using a powerful SQL language interface.
ISB-CGC stores high-level clinical, biospecimen, and molecular data from the main NCI programs in the BigQuery projects isb-cgc-bq and isb-cgc. It also stores a large amount of metadata about files that are stored in the GDC Google Cloud Storage, as well as genome reference sources (e.g. GENCODE, miRBase, etc.). Most of these data sets and tables are completely open access and available to the research community.
Terms of Use
Using the data stored in ISB-CGC is subject to the terms of use of its origin.
Genomic Data Commons (GDC) Data Access Policies
Proteomics Data Commons (PDC) Data Use Guidelines
The Cancer Imaging Archive (TCIA) Data Usage Policies and Restrictions
The Cancer Research Data Commons (CRDC) Data Use Policy Statement
For reference and other tables, see the table description for specific information.